


When summarising a document, we do damage to various aspects of the document's coherency. These aspects will be covered below under four topics: paragraphing, punctuation, referring expressions and discourse markers.
Deleting sentences without changing paragraph boundaries would produce a text of many short paragraphs, reducing readability. Rather than attempt to repair document paragraphing, we have found it easier to throw away the original paragraphing, and re-determine paragraph boundaries as described below.
Paragraphing within a document is intended to make it easier to read. It segments the discourse into small chunks of sentences which are to some degree highly related. We found it plausible to use our RST structure to help in determining paragraph boundaries. From looking at texts, it is the usual case to see a paragraph representing a nucleus and its satellites (although some other of its satellites be in other paragraphs).
There is a useful notion used in speech synthesis and generation which claims that the spacing between spoken words can be predicted largely by the syntactic distance between them -- the number of branches which have to be traversed in the parse tree to move from one word to the other. Thus, in the Girl Guides fish, we would expect little pause between noun Guides and its modifier Girl, while in the homophone the girl guides fish we would expect more pause between the verb guides and the subject girl.
We have applied this principle to paragraphing, arguing that
two adjacent sentences which are more discoursally distant
(more structurally separated in terms of the RST-tree) are more
likely to be separated by a paragraph break.
This is not the whole story however. Paragraphing is also constrained by the needs of paragraphic rhythm. Martinec (1995) argues that the division of texts into paragraphs is similar to the rhythmic structure of the sentence (divided into tonic feet of similar interval). Both are means of organising information into manageable chunks. The rhythm of a text requires that these chunks are of approximately the same size, not too long, not too short.
Our paragraphing algorithm combines these two notions -- semantic distance and paragraphic rhythm -- to determine paragraph boundaries in the presented texts. We assume there is an ``ideal'' paragraph length for the text, the paragraph rhythm (user configurable). Starting at the beginning of the text, we test each point between sentences for a possible paragraph-break. We evaluate two factors:
We use the following formula to evaluate each possible paragraph break, and select the point with the lowest value (I will leave fuller explanation to a paper dedicated to the topic):
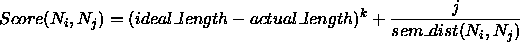
...where ideal_length, k and j are constants. I have found best results with values of 150, 1.2 and 75. Lower values of k allow more variation of paragraph size in seeking for better breaks on semantic distance grounds.
Once a paragraph position is selected, we take that as our starting point and look for the next paragraph boundary after that, until the end of the text is reached. As you can see from figures 1 and 2 (both paragraphed using the above formula), the method produces quite plausible paragraphing.
As reported above, we have allowed the RST Tool to assign structure within the sentence as well as between sentences. This however creates a problem because, in deleting an intra-sentence nucleus, we may also delete the punctuation it carries. For instance, in (N: Edward surrendered,)(S: in 1245), deletion of the nucleus leaves us with a sentence terminated by a comma.
One module of the present system has been developed to correct such problems. It ensures all sentences start with a capital, and recovers the sentence-terminating punctuation from any pruned segments where necessary.
When deleting sections of a text, we may destroy the referential cohesion of a text in two ways. Firstly, we might delete the introduction of an entity, which provided the entities name, or other characteristics which allow the reader to identify the entity correctly. The remaining text may refer to this entity (e.g., ``he''), but leave no clue as to who the entity is. The second, related, problem involves changing the referential environment of entities. References which are contextually unambiguous in the full text may be brought into close proximity to other entities which are potential confusers.
In the system as implemented so far, there has been no attempt to correct these problems. Cases of problems have been rare. However, for the next stage of implementation we are planning to introduce NP markup into the document preparation stage, allowing the document editor to indicate co-reference of NPs in the text. This would be a simple matter of allowing the editor to drag from each NP to a co-referring NP.
From this markup, we can deduce various things. We can identify the first-occurring reference for each entity, and with a reasonable level of certainty, use this as the first-mention of the entity in any pruned-text. We can analyse the remaining references to discover gender (from pronouns) or class (from definite or indefinite references). Where text-pruning places two entities of similar gender in proximity, the class-based or name-based reference form could be used if available. In this way, many of the reference problems can be repaired. An anaphora generation module being developed by Janet Hitzeman is a good candidate for use here.
The extra cost of NP markup needs to be weighed against the gain of coherency gained.
Markers of rhetorical relations are usually attached to satellites,
and so there is no problem when the satellite is pruned. However, in
some peoples analyses, some relations mark the nucleus, not the
satellite. In others, both the nucleus and satellite are marked (e.g.,
if/then). When we delete the satellite, we should ensure that the
discourse marker is removed also from the nucleus. However, due to the
rarity of nucleus marking, this problem rarely occurs.
For those cases where nucleus marking does occur, a future applications might avoid the problem by removing all discourse markers from the marked-up text, and generating these as appropriate. However, I envisage problems associated with this approach, including over-generation of discourse linkers (many are left implicit).