


Rather than expanding out the whole grammar, it is more efficient to extract out subsets of the grammar, to be used for particular tasks in parsing. In our systemic parser, the description is used for three purposes:
Each of these uses makes only partial use of the grammar description. Thus, rather than expanding out the entire grammar, we can simplify the process by extracting out sub-grammars, one for each of these applications. Since the size of each sub-grammar is smaller, the complexity problem is reduced. This section looks at these three sub-descriptions in more detail.
It has proved useful to separate the type logic component of the grammar from the role logic. The two logic components have different patterns of use -- type logic is used to test whether two partial type-paths can unify. We never try to unify a partial type description with the type grammar as a whole. The type-logic component of the grammar thus does not need to be DNF-expanded.
The role logic, on the other hand, does need to be expanded. We expand the role-logic component to produce a set of non-disjunctive structure rules which can be applied during parsing (sometimes termed `chunkingŐ).
Thse two components of the description have different properties: type logic is acyclic, while role logic is potentially cyclic. Type logic is constrained such that types are always in disjoint coverings (which allows efficient negation), while role logic doesn't have this constraint.
Because of these differences in properties and uses, it has proved efficient to treat these two logics separately. Logical Form I of the systemic grammar provided in Figure 3 can be re-represented in the equivalent Logical form II shown in Figure 4, separating out the type and role logic.
: Logical Form II of the Grammar
The parser uses the type-logic component of this
grammar without fully expanding it. Partial
expansion, however, is performed, whereby the
type-path (the logical-entailment of a system, i.e.,
the logical expression of types leading back to the
root of the network) is pre-compiled for each
system. The negation of each type in the system is
also pre-compiled, which speeds up unification
involving negation of types.
is pre-compiled for each
system. The negation of each type in the system is
also pre-compiled, which speeds up unification
involving negation of types.
Type-paths are represented in the form proposed by Kasper (1987), and his unification algorithm is used when two type-paths are unified. The main use of the type-logic component is checking the compatibility of two types or type-paths.
Type logic has thus been simplified using three strategies:
Another use made of the grammatical description in parsing is to assign a set of structural roles to a unit. The set of roles a unit fills is called in Systemics the function-bundle of the unit. The systemic formalism allows each unit to be assigned multiple functions. For instance, using the NIGEL grammar, 'the cat' in ``the cat scratched the woman'' would be assigned the function-bundle Subject/Agent/Actor/Theme. The possibility of a unit serving multiple functions is a major source of complexity in systemic parsing.
Assigning function-bundles to a unit is one of the tasks in systemic parsing. For instance, assume we have just parsed a pronoun ``he'', assigning it a type-path:
(:and word:pronoun:nominative:human:singular)
Now, we wish to find what function-bundles the pronoun can serve at a higher level. One result could be as in figure 5.
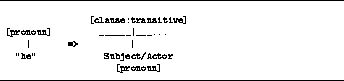
Figure 5: Assigning Function Bundle to a lexeme
This process draws upon three parts of our grammar:
For the function-assignment process, we do not need all of the role logic description. We can select out only those rules involving preselection, lexify, and conflation. See Logical Form III in Figure 6.

Figure 6: Logical Form III: The Function Assignment Sub-Description
We next put this description into a form more suitable for DNF-expansion. Note that implication can be re-expressed using disjunction, conjunction and negation:
(:implies a b) is-equivalent-to
(:xor (:and a b) (:not a))
Using this rule, we can re-express the logical form III as Logical Form IV, as shown in Figure 7.

Figure 7: Logical Form Form IV: After Implications-Out
Simple algorithms exist to expand Logical Form IV into DNF (see section 5.1). A small part of the result appears in Logical Form V of the grammar, shown in Figure 8.

Figure 8: Logical Form Form V: After DNF-Expansion
The order of worst-case complexity of the expansion to DNF is easily calculated -- it is simply two to the power of the number of disjunctions, which is equal to the number of types which have realisation rules of type conflation, insertion, or preselection.
By opting to expand only subsets of the whole grammar, we have reduced the complexity of the description, since the size of n for this sub-description is smaller than for the whole description. However, for a real-sized grammar such as NIGEL, the size of n is still large.
From the DNF-form of this description, we can extract out partial-descriptions for each function bundle. We now re-express this logical form in terms of the type constraints on each function-bundle, including both the constraint on the type of unit the function-bundle can be part of (the `parent-constraint'), and the constraint on the filler of the function-bundle (the `filler-constraint'). We show this as a set of triplets, of the form:
( <parent-types> <function-bundle> <child-types> )
1. ( (:and clause transitive
active single-subject)
Subject/Actor
(:and nominative human singular)))
2. ( (:and clause transitive
active single-subject)
Object/Actee
accusative)))
3. ( (:and clause transitive
active plural-subject)
Subject/Actor
(:and nominative human plural)
4. ( (:and clause transitive
active plural-subject)
Object/Actee
accusative)
5. ( (:and clause transitive
active singular-subject
Finite/Pred
(:and verb finite-verb lexical-verb))
etc....
This representation can now be used to assign function-bundles A unit can take on a function-bundle if it can unify with the filler-constraint on the function-bundle.
For the instance we started with, "he", with types: (:and pronoun nominative human singular), only one triplet would unify. We could thus posit structure for our unit:
[clause:transitive:active:single-subject]
..__________|__________...
|
Subject/Actor
|
[ pronoun:nominative:human:singular ]
|
"he"
Note that we have also gained information about the types of the parent-unit of which the unit is a constituent.
Note that there is another simplification we can make to the triplet list. We can take all triplets with identical function bundle and child-type specification, and join them. The parent-types slot is replaced with the disjunction of the two parent-type slots. Thus, elements 2 and 4 above become a single item. This process reduces the number of rules to apply:
2,4. ( (:and clause transitive active)
Object/Actee
accusative)))
Another process we use in parsing involves the prediction of what function-bundles can come next in a partially completed structure. With a systemic grammar, this process requires:
Another means of reducing the overall complexity of the descriptions involves eliminating from the grammar parts which are unlikely to be utilised in the target texts. In systemic terms, we apply register restrictions to the grammar.
For example, in a domain of computer manuals,
the description of interrogative structures is not
likely to be drawn upon. By eliminating this sub-description,
we reduce the degree of disjunction in
the whole description, and thus speed up the parsing
of the forms which do appear in the text.
The method of deriving the register-restrictions was as follows:
a chapter of the
computer manuals we were attempting to parse,
building up a register-profile of our target texts.
By extracting out sub-descriptions from the full description, we reduce the complexity of the description-to-be-expanded.
